1 GANs的Generator
1.1 Generator
接下来要进入一个,新的主题 我们要讲生成这件事情
传统的神经网络,都是给定$x$,得到输出$y$。
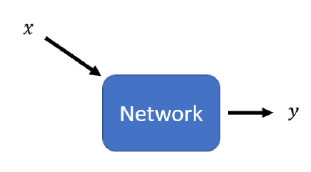
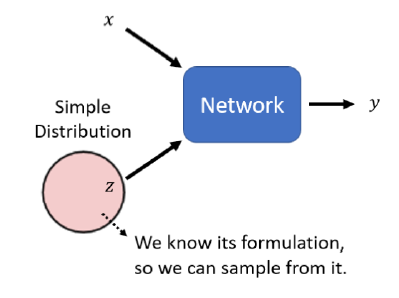
而GANs则是输入一个随机变量$z$和$x$一起,共同生成$y$。也就是说网络的输出结果和$x,y$都有关。
随机变量$z$可以从任意分部sample出来,通常是一个数组。对于分布有一个限制,就是它必须足够简单,也就是我们知道它的式子是什么样子。
$z$通常从正态分布中获取。
由于每次输入的$z$不同,所以$y=network(x,z)$也不同。网络会将$z$从简单的分布映射到复杂的分布。
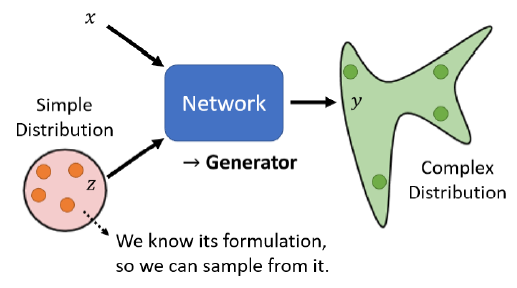
因此,这个网络也叫做Generator。
1.2 Discriminator
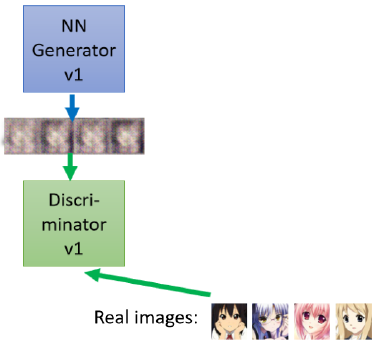
除了generator,GAN中还要训练一个discriminator,来判别样本是真的样本,还是generator做的假样本。用来强化generator。
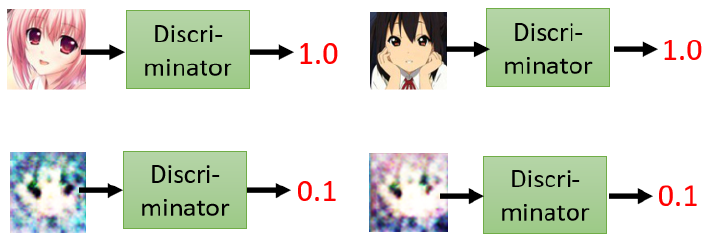
discriminator会和generator在训练过程中共同进步。
假设第一代generator生成的图片很模糊,那么discriminator也不需要太强,很容易就可以区分出真假图片。
因此,第二代generator就就会学着去做出更接近真实的图片,尝试骗过discriminator。
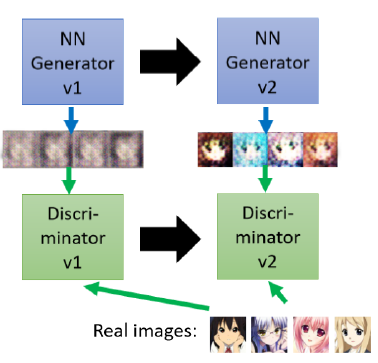
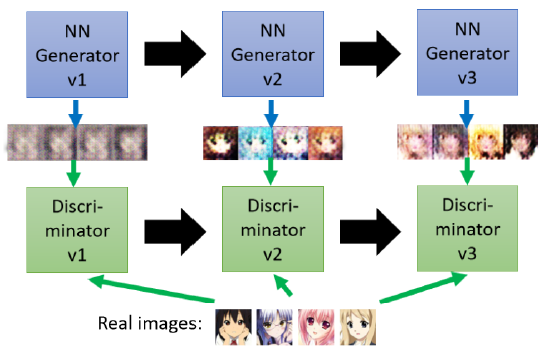
而discriminator也会进化,就变成第二代的discriminator,他会去学习分辨二代generator产生的假图片,他们就这样一直持续对抗下去,discriminator的要求会越来越高,generator的伪造能力也会因此变得越来越强。
2 为什么使用随机分布?
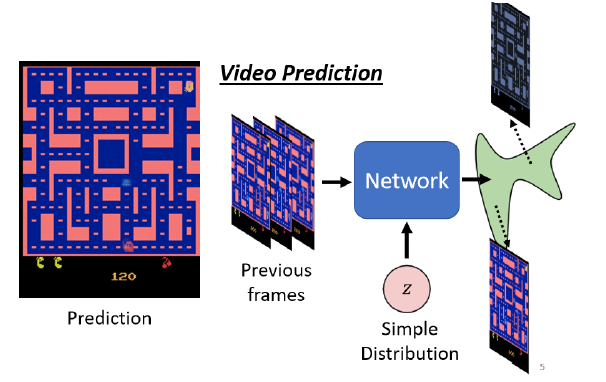
为什么不使用固定的$x$来得到$y$呢?李宏毅在客户举了一个例子,Video Prediction任务中,目的为预测Pac Man游戏下一帧的画面,可以设置如下任务:
- $x$:当前帧$x_i$
- $target$:下一帧$x_{i+1}$
- 算法:supervised learning
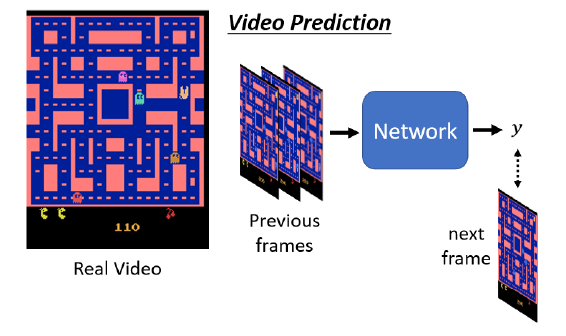
按照上面的方法,模型结果可能会导致如下情况:
- 图像模糊
- 角色可能会突然变换
- 角色转弯时,可能会分裂(因为左右转概率都很高,所以存在两种可能,因此模型两边讨好)
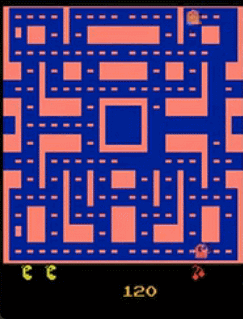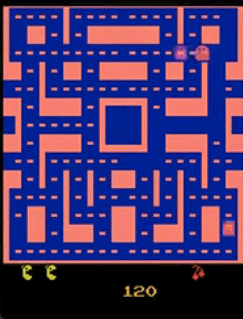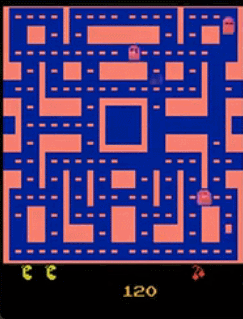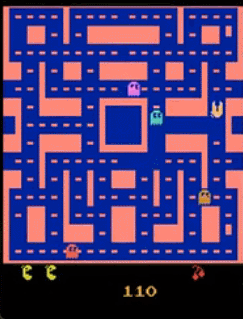
因此,我们希望通过$z$,似的模型的输出是有机率的,不再是输出单一的输出,而是输出一个概率的分布。比如在$z=[1]$的时候向左转,而$z=[0]$的时候向右转。这样一来,我们给模型附加了创造力。
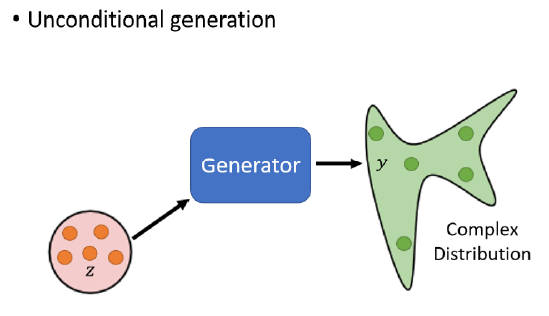
3 Unconditional/Conditional Generation
Unconditional generation,就是在输入中把$x$拿掉,generator的输入只有$z$
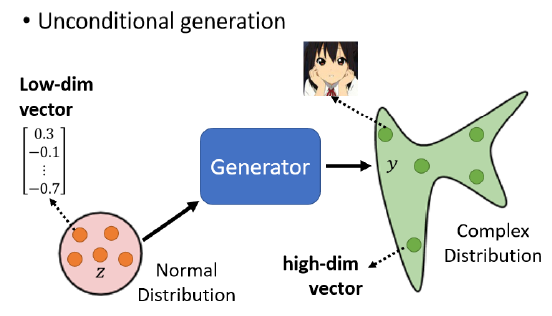
而conditional generation则是在输入中把$x$加回来,
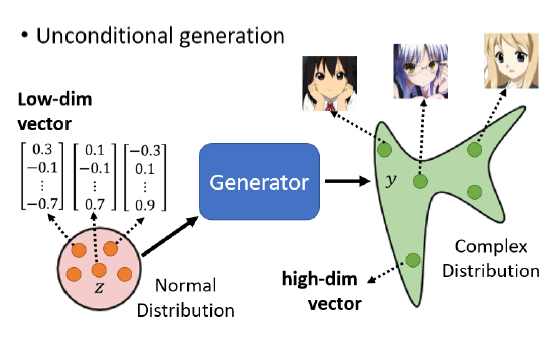
在unconditional generation中,模型会根据不同的$z$输出不同的人脸。
4 GAN的算法
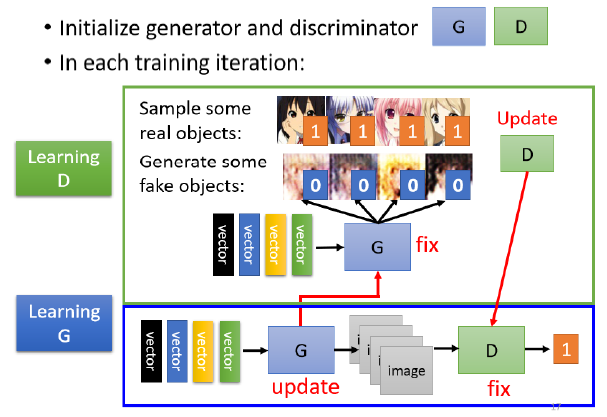
Generator和discriminator,是两个神经网络,需要相互对抗来进步,因此他们是迭代训练的。
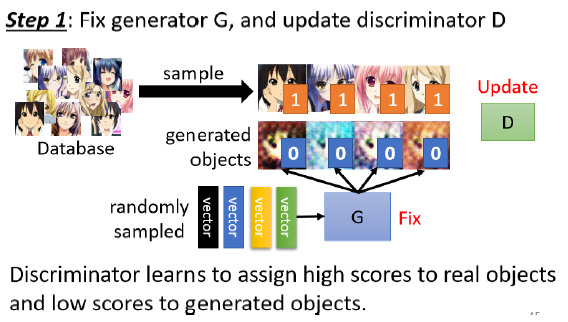
Step 1: 固定 generator G, 然后 update discriminator D
在初始化G和D以后,首先定住G,来训练D。
分别把真实图片和G生成的图片输入给D,让D去学着分类。真图片的label是1,假图片的label是0
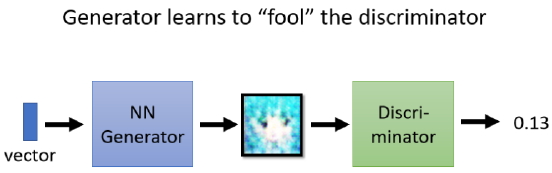
Step 2: 固定discriminator D, 然后 update generator G
在训练完D之后,固定住D,来训练G,尝试让G想办法去骗过D。
这两个步骤会反复迭代进行:
- 第一个步骤 固定generator,训练discriminator
- 第二个步骤,固定discriminator训练generator
generator和discriminator会不断变得更强。
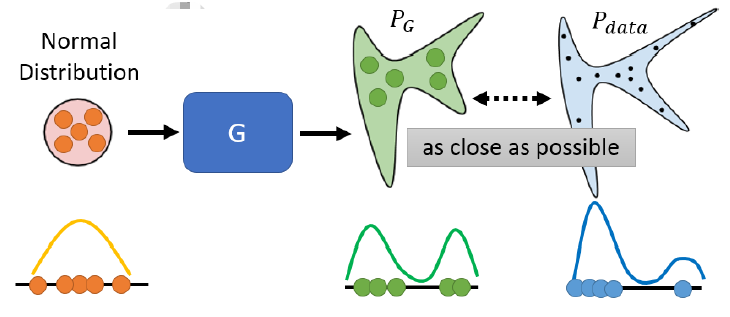
5 GANs的理论
在GAN中我们要让我们的Generator将输入的简单分布输出为复杂分布。假设复杂分布为$P_G$,而真实分布为$P_{data}$。我们期待 PG 跟 Pdata 越接近越好。
以简单分布为一维的情况为例:
假设:
- Generator 的 Input 是一个一维的向量
- Generator 的 Output 也是一维的向量
- 真正的 Data 也是一维的向量
Generator的输入是Normal Distribution,分布 如下:

假设Generator输出的分布$P_G$如下:

而 真实的分布$P_{data}$如下:
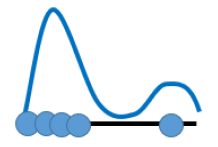
我们希望两者越近越好,那么可以计算他们的divergence(散度),Divergence越小则两个分布越接近。Divergence最小的generator为$G^\star$。
$$ G^{*}=\arg \min _{G} \operatorname{Div}\left(P_{G}, P_{\text {data }}\right) $$
常见的divergence 的式子包括 KL Divergence和JS Divergence,这种divergence 用在这种Continues Distribution 上计算,需要做积分,这是很难实现的,所以不知道怎么计算divergence。这也就是 GAN 目前遇到的问题。
GAN的解决办法是你不需要知道$P_G$ 跟 $P_{data}$的公式,只要能从 $P_G$ 和 $P_{data}$这两个分布中做sample,就可以计算divergence。
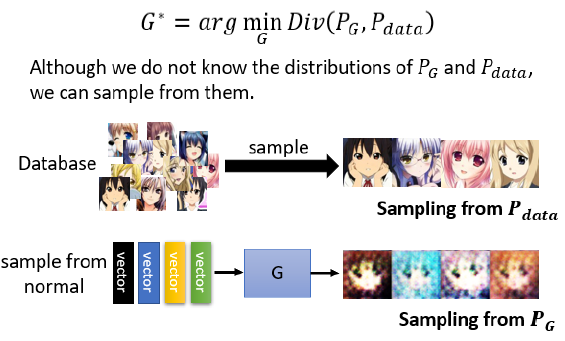
大概步骤:
- 从真实图片中随机sample一些图片,作为$P_{data}$
- 从normal distribution中做sample,作为generator的输出,而generator的输出就是$P_G$
6 Discriminator的优化
Discriminator的目标是最大化Divergence,所以它的objective function是:
$$ V(G, D)=E_{y \sim P_{d a t a}}[\log D(y)]+E_{y \sim P_{G}}[\log (1-D(y))] $$
- $E_{y\sim P_{data}}[logD(y)]$ :输入为真实图片,$D(y)$预测越接近1,则越准确;因此$\log D(y)$越大越好
- $E_{y\sim P_G}[log(1-D(y))]$ 输入为generator生成的图片,$D(y)$预测越接近0越准确;因此,$log(1 - D (y))$
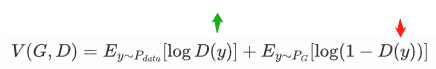
这个 Objective Function 就是 Cross Entropy 乘一个负号,相当于我们要最大化这个式子,相当于最小化交叉熵。等于训练一个分类器。
而且,$\max V(D,G)$还和 JS Divergence 有关。大概可以理解为:假设 $P_G$ 跟 $P{data}$的 Divergence 很小,那么$\max V(D,G)$也会很小,反之亦然。
因此,我们希望generator去最小化divergence $Div(P_G,P_{data})$ 相当于最小化$\max\limits_D V(D,G)$。
$$ \begin{aligned} &G^{*}=\arg \min _{G} \operatorname{Div}\left(P_{G}, P_{d a t a}\right)\\ &D^{*}=\arg \max _{D} V(D, G) \quad \begin{aligned} &\text { The maximum objective value } \\ &\text { is related to JS divergence. } \end{aligned} \end{aligned} $$
当然,除了JS Divergence,也可以用KL Divergence等等。

7 GAN的效果
GAN在某个生成动漫图像任务中的效果如下:
Train 100次:

Train 1000次:

Train 2000次:

Train 5000次:

Train 10000次:

Train 20000次:

Train 50000次:

除此之外,下面图片是用StyleGAN做出来的效果:

下面是progressive GAN做出的人脸模拟的效果:

甚至可以通过控制$z$,来实现人脸的细微变换。
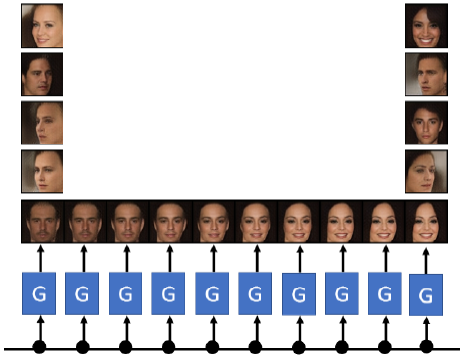
甚至可以控制表情。
