1 安装detectron2
1.1 基于docker安装
基于docker安装,可以参考github链接
1.2 直接安装
Option A:
- 安装
cuda10.2 安装
pytorch 1.8.0+cuda10.2和detectron2pip install torch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 pip install 'git+https://github.com/facebookresearch/detectron2.git'
Option B:
用conda直接安装pytorch+cuda
2 跑通demo
2.1 demo预测脚本
%%writefile predictor.py
# Copyright (c) Facebook, Inc. and its affiliates.
import atexit
import bisect
import multiprocessing as mp
from collections import deque
import cv2
import torch
from detectron2.data import MetadataCatalog
from detectron2.engine.defaults import DefaultPredictor
from detectron2.utils.video_visualizer import VideoVisualizer
from detectron2.utils.visualizer import ColorMode, Visualizer
class VisualizationDemo(object):
def __init__(self, cfg, instance_mode=ColorMode.IMAGE, parallel=False):
"""
Args:
cfg (CfgNode):
instance_mode (ColorMode):
parallel (bool): whether to run the model in different processes from visualization.
Useful since the visualization logic can be slow.
"""
self.metadata = MetadataCatalog.get(
cfg.DATASETS.TEST[0] if len(cfg.DATASETS.TEST) else "__unused"
)
self.cpu_device = torch.device("cpu")
self.instance_mode = instance_mode
self.parallel = parallel
if parallel:
num_gpu = torch.cuda.device_count()
self.predictor = AsyncPredictor(cfg, num_gpus=num_gpu)
else:
self.predictor = DefaultPredictor(cfg)
def run_on_image(self, image):
"""
Args:
image (np.ndarray): an image of shape (H, W, C) (in BGR order).
This is the format used by OpenCV.
Returns:
predictions (dict): the output of the model.
vis_output (VisImage): the visualized image output.
"""
vis_output = None
predictions = self.predictor(image)
# Convert image from OpenCV BGR format to Matplotlib RGB format.
image = image[:, :, ::-1]
visualizer = Visualizer(image, self.metadata, instance_mode=self.instance_mode)
if "panoptic_seg" in predictions:
panoptic_seg, segments_info = predictions["panoptic_seg"]
vis_output = visualizer.draw_panoptic_seg_predictions(
panoptic_seg.to(self.cpu_device), segments_info
)
else:
if "sem_seg" in predictions:
vis_output = visualizer.draw_sem_seg(
predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
)
if "instances" in predictions:
instances = predictions["instances"].to(self.cpu_device)
vis_output = visualizer.draw_instance_predictions(predictions=instances)
return predictions, vis_output
def _frame_from_video(self, video):
while video.isOpened():
success, frame = video.read()
if success:
yield frame
else:
break
def run_on_video(self, video):
"""
Visualizes predictions on frames of the input video.
Args:
video (cv2.VideoCapture): a :class:`VideoCapture` object, whose source can be
either a webcam or a video file.
Yields:
ndarray: BGR visualizations of each video frame.
"""
video_visualizer = VideoVisualizer(self.metadata, self.instance_mode)
def process_predictions(frame, predictions):
frame = cv2.cvtColor(frame, cv2.COLOR_BGR2RGB)
if "panoptic_seg" in predictions:
panoptic_seg, segments_info = predictions["panoptic_seg"]
vis_frame = video_visualizer.draw_panoptic_seg_predictions(
frame, panoptic_seg.to(self.cpu_device), segments_info
)
elif "instances" in predictions:
predictions = predictions["instances"].to(self.cpu_device)
vis_frame = video_visualizer.draw_instance_predictions(frame, predictions)
elif "sem_seg" in predictions:
vis_frame = video_visualizer.draw_sem_seg(
frame, predictions["sem_seg"].argmax(dim=0).to(self.cpu_device)
)
# Converts Matplotlib RGB format to OpenCV BGR format
vis_frame = cv2.cvtColor(vis_frame.get_image(), cv2.COLOR_RGB2BGR)
return vis_frame
frame_gen = self._frame_from_video(video)
if self.parallel:
buffer_size = self.predictor.default_buffer_size
frame_data = deque()
for cnt, frame in enumerate(frame_gen):
frame_data.append(frame)
self.predictor.put(frame)
if cnt >= buffer_size:
frame = frame_data.popleft()
predictions = self.predictor.get()
yield process_predictions(frame, predictions)
while len(frame_data):
frame = frame_data.popleft()
predictions = self.predictor.get()
yield process_predictions(frame, predictions)
else:
for frame in frame_gen:
yield process_predictions(frame, self.predictor(frame))
class AsyncPredictor:
"""
A predictor that runs the model asynchronously, possibly on >1 GPUs.
Because rendering the visualization takes considerably amount of time,
this helps improve throughput a little bit when rendering videos.
"""
class _StopToken:
pass
class _PredictWorker(mp.Process):
def __init__(self, cfg, task_queue, result_queue):
self.cfg = cfg
self.task_queue = task_queue
self.result_queue = result_queue
super().__init__()
def run(self):
predictor = DefaultPredictor(self.cfg)
while True:
task = self.task_queue.get()
if isinstance(task, AsyncPredictor._StopToken):
break
idx, data = task
result = predictor(data)
self.result_queue.put((idx, result))
def __init__(self, cfg, num_gpus: int = 1):
"""
Args:
cfg (CfgNode):
num_gpus (int): if 0, will run on CPU
"""
num_workers = max(num_gpus, 1)
self.task_queue = mp.Queue(maxsize=num_workers * 3)
self.result_queue = mp.Queue(maxsize=num_workers * 3)
self.procs = []
for gpuid in range(max(num_gpus, 1)):
cfg = cfg.clone()
cfg.defrost()
cfg.MODEL.DEVICE = "cuda:{}".format(gpuid) if num_gpus > 0 else "cpu"
self.procs.append(
AsyncPredictor._PredictWorker(cfg, self.task_queue, self.result_queue)
)
self.put_idx = 0
self.get_idx = 0
self.result_rank = []
self.result_data = []
for p in self.procs:
p.start()
atexit.register(self.shutdown)
def put(self, image):
self.put_idx += 1
self.task_queue.put((self.put_idx, image))
def get(self):
self.get_idx += 1 # the index needed for this request
if len(self.result_rank) and self.result_rank[0] == self.get_idx:
res = self.result_data[0]
del self.result_data[0], self.result_rank[0]
return res
while True:
# make sure the results are returned in the correct order
idx, res = self.result_queue.get()
if idx == self.get_idx:
return res
insert = bisect.bisect(self.result_rank, idx)
self.result_rank.insert(insert, idx)
self.result_data.insert(insert, res)
def __len__(self):
return self.put_idx - self.get_idx
def __call__(self, image):
self.put(image)
return self.get()
def shutdown(self):
for _ in self.procs:
self.task_queue.put(AsyncPredictor._StopToken())
@property
def default_buffer_size(self):
return len(self.procs) * 5
2.2 mask rcnn配置文档
%%writefile cascade_mask_rcnn_R_50_FPN_1x.yaml
_BASE_: "./Base-RCNN-FPN.yaml"
MODEL:
WEIGHTS: "model_final_e9d89b.pkl"
MASK_ON: True
RESNETS:
DEPTH: 50
ROI_HEADS:
NAME: CascadeROIHeads
ROI_BOX_HEAD:
CLS_AGNOSTIC_BBOX_REG: True
RPN:
POST_NMS_TOPK_TRAIN: 2000
2.3 底层RCNN-FPN配置文档
%%writefile Base-RCNN-FPN.yaml
MODEL:
META_ARCHITECTURE: "GeneralizedRCNN"
BACKBONE:
NAME: "build_resnet_fpn_backbone"
RESNETS:
OUT_FEATURES: ["res2", "res3", "res4", "res5"]
FPN:
IN_FEATURES: ["res2", "res3", "res4", "res5"]
ANCHOR_GENERATOR:
SIZES: [[32], [64], [128], [256], [512]] # One size for each in feature map
ASPECT_RATIOS: [[0.5, 1.0, 2.0]] # Three aspect ratios (same for all in feature maps)
RPN:
IN_FEATURES: ["p2", "p3", "p4", "p5", "p6"]
PRE_NMS_TOPK_TRAIN: 2000 # Per FPN level
PRE_NMS_TOPK_TEST: 1000 # Per FPN level
# Detectron1 uses 2000 proposals per-batch,
# (See "modeling/rpn/rpn_outputs.py" for details of this legacy issue)
# which is approximately 1000 proposals per-image since the default batch size for FPN is 2.
POST_NMS_TOPK_TRAIN: 1000
POST_NMS_TOPK_TEST: 1000
ROI_HEADS:
NAME: "StandardROIHeads"
IN_FEATURES: ["p2", "p3", "p4", "p5"]
ROI_BOX_HEAD:
NAME: "FastRCNNConvFCHead"
NUM_FC: 2
POOLER_RESOLUTION: 7
ROI_MASK_HEAD:
NAME: "MaskRCNNConvUpsampleHead"
NUM_CONV: 4
POOLER_RESOLUTION: 14
DATASETS:
TRAIN: ("coco_2017_train",)
TEST: ("coco_2017_val",)
SOLVER:
IMS_PER_BATCH: 16
BASE_LR: 0.02
STEPS: (60000, 80000)
MAX_ITER: 90000
INPUT:
MIN_SIZE_TRAIN: (640, 672, 704, 736, 768, 800)
VERSION: 2
2.4 下载权重文件
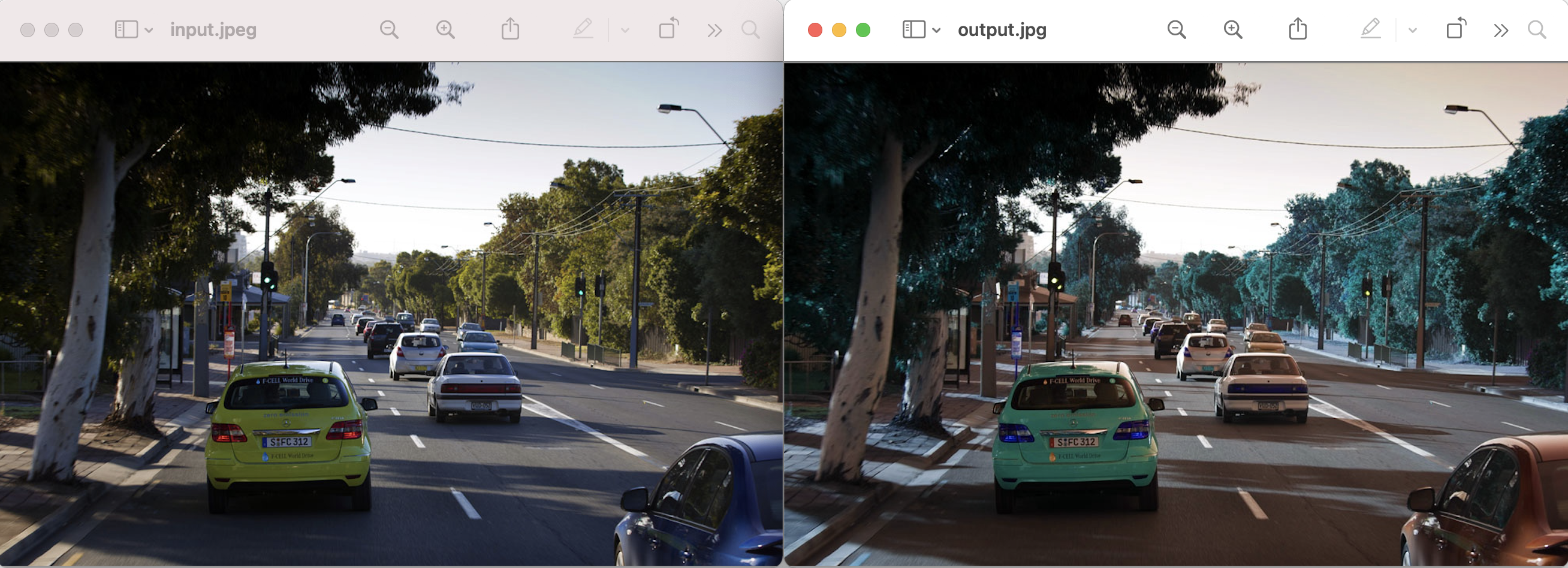
!wget https://dl.fbaipublicfiles.com/detectron2/Misc/cascade_mask_rcnn_R_50_FPN_1x/138602847/model_final_e9d89b.pkl2.5 准备一张图片,命名为input.jpg
3 开始跑
3.1 导入所需的包
from predictor import VisualizationDemo
from detectron2.config import get_cfg
import cv23.2跑demo
def setup_cfg(config_file):
cfg = get_cfg()
cfg.merge_from_file(config_file)
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5
cfg.freeze()
return cfg
if __name__ == '__main__':
path = './cascade_mask_rcnn_R_50_FPN_1x.yaml'
pic = './input.jpg'
output = './output.jpg'
cfg = setup_cfg(path)
demo = VisualizationDemo(cfg)
pic_image = cv2.imread(pic)
detect_res = demo.run_on_image(pic_image)
cv2.imwrite(output, detect_res[1].img)最终输出在output.jpg中的图片效果为(左为原始图片,右为处理后的图片):