1 为什么JS Divergence不适合GAN?
在上一篇中,聊到了$P_G$和$P_{data}$ 这两个分布,但是在高维空间,他们的overlap通常会非常少。为了形象展示,使用一维来举例:
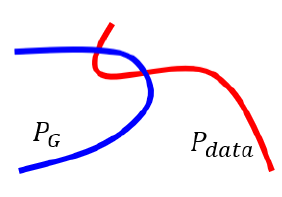
我们可以认为,$P_G$和$P_{data}$ 是高维空间中的一个低维的 manifold(流形)是可以局部欧几里得空间的一个拓扑空间,是欧几里得空间中的曲线、曲面等概念的推广)正如上图所示,它们相交的范围,几乎是可以忽略的。
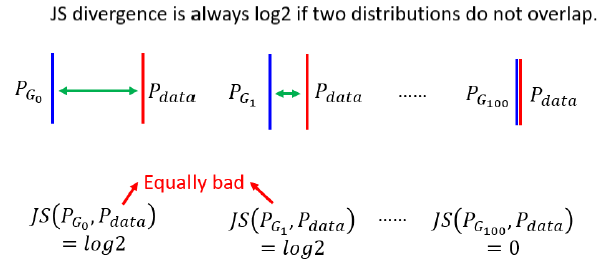
对于没有overlap的JS Divergence,有一个问题。JS Divergence 有一个特性:两个不重叠的分布的JS Divergence就永远都是$\log 2$,不管这两个分布距离多近。
此外,没有人知道$P_G$和$P_{data}$ 实际的分布,只是从其中sample数据才能窥得一二。
即使$P_G$和$P_{data}$ 和Overlap 的范围很大,我们也仅仅是Sample一些点出来,如果 Sample 的点不够多,不够密,就算是这两个 Divergence 很低,但对 Discriminator 来说,也可以很容易的分出他们,所以它的正确率接近100%,预测的divergence会很高。然而,GAN在训练中并没有出现这种情况,所以WGAN之前的GAN都像魔法一样,不确定为什么能生效。
WGAN就是基于 JS Divergence 的问题,把它换成了 Wasserstein Distance。
2 Wasserstein Distance
Wasserstein Distance 的想法如下:
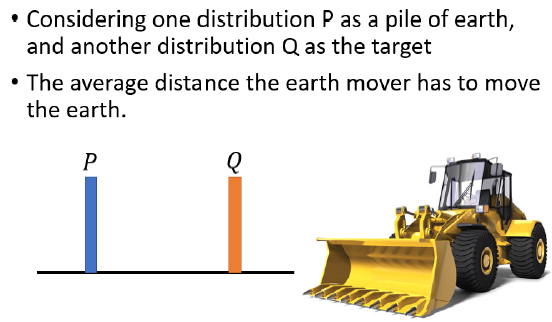
假设有两个 Distribution $P$和$Q$,Wasserstein Distance 的计算方法,可以想象为在开一台推土机,把 $P $想成是一堆土,把 $Q$ 想成是你要把土堆放的目的地,那这个推土机把 P 这边的土,挪到 Q 所移动的平均距离,就是 Wasserstein Distance
但是如果是更复杂的 Distribution,很难算 Wasserstein Distance
下方的分布有很多种方法,我们无法穷举全部的方法。
Wasserstein Distance 只能有一个值,所以对 Wasserstein Distance 的定义是,穷举所有的 Moving Plans,然后看哪一个推土的方法,哪一个 Moving 的计划,可以让平均的距离最小,那个最小的值,才是 Wasserstein Distance
所以其实要计算 Wasserstein Distance,是挺麻烦的,光只是要计算一个 Distance,居然还要解一个 Optimization 的问题,解出这个 Optimization 的问题,才能算 Wasserstein Distance
如果能够计算Wasserstein Distance,我们就能知道两个分布相差多少了。
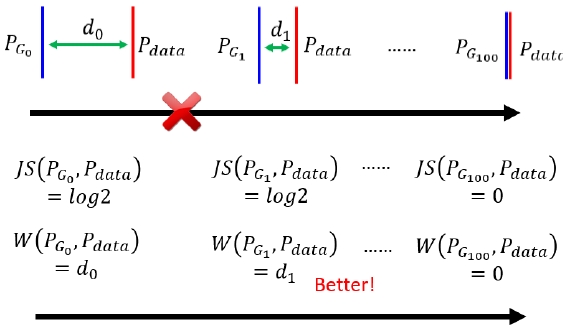
那假设 PG 跟 Pdata 它们的距离是 $d_0$,在左边这个例子裡面,Wasserstein Distance 算出来就是 $d_0$
在中间这个例子裡面,PG 跟 Pdata 它们之间的距离是 $d_1$,那 Wasserstein Distance 算出来的距离,就是 $d_1$
假设 $d_1$ 比较小,$d_0$ 比较大,那算 Wasserstein Distance 的时候,这个 Case 的 Wasserstein Distance 就比较小,这个 Case 的 Wasserstein Distance 就比较大,所以我们就可以知道说,由左向右的时候,Wasserstein Distance 是越来越小的
所以如果你观察,Wasserstein Distance 的话会知道说,从左到右我们的 Generator 越来越进步,但是如果你观察 Discriminator,你会发现你观察不到任何东西,对 Discriminator 而言,这边每一个 Case 算出来的 JS Divergence,都是一样,都是一样好或一样差,但是如果换成 Wasserstein Distance,由左向右的时候我们会知道说,我们的 Discriminator 做,我们的 Generator 做得越来越好
所以我们换一个计算 Divergence 的方式,我们就可以解决 JS Divergence,有可能带来的问题
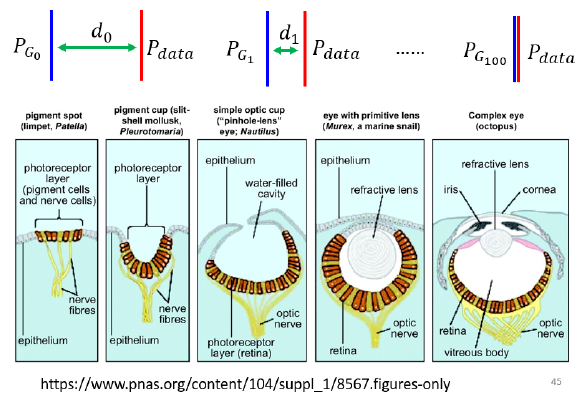
这又让我想到一个演化的例子,这是眼睛的生成

右边这个是人类的眼睛,人类的眼睛是非常地复杂的,那有一些生物它有非常原始的眼睛,比如说有一些细胞具备有感光的能力,这可以看做是最原始的眼睛,但是这些最原始的眼睛,怎麼变成最复杂的眼睛,这对人类来说其实觉得非常难想像
左边这个图像构造这麼简单,只是一些感光的细胞在皮肤上,经过突变產生一些感光的细胞,听起来像是一个合理的,但是天择突变,怎麼可能產生这麼复杂的器官,怎麼產生眼睛这麼精巧的器官
那如果你直接觉得说,从这个地方就可以一步跳到这个地方,那根本不可能发生,但是中间其实是有很多连续的步骤,从感光细胞到眼睛,中间其实是有连续的步骤的
WGAN 实际上就是用 Wasserstein Distance取代 JS Divergence。实际上,WGAN计算的函数如果不去做推导,只看结论非常简单,就是让discriminator优化下面这个函数。
$$ \max _{D \in 1-L i p s c h i t z}\left\{E_{y \sim P_{d a t a}}[D(y)]-E_{y \sim P_{G}}[D(y)]\right\} $$
实际上就是看$P_G$和$P_{data}$的期望值的差距。
然而,其中有一个$1-L i p s c h i t z$限制,就是$D$要足够smooth,所以它不能是一个随便的函数。大概可以理解为,不能给$P_G$样本太小的负值,也不能给$P_{data}$太大的正值。要正确分开他们,还要让他们不要差太大。 否则我们算出的Wasserstein Distance也会接近无穷。
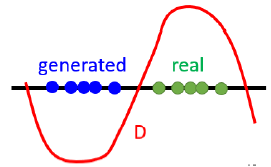
原始的WGAN使用一个简单粗暴的方法,就是直接剪裁discriminator的$w$的权重,让他们在$[-c,c]$范围。

3 WGAN-GP和Spectral Normalization
传统WGAN的方法太粗暴,有一个优化版,WGAN Gradient Penalty,简称WGAN-GP
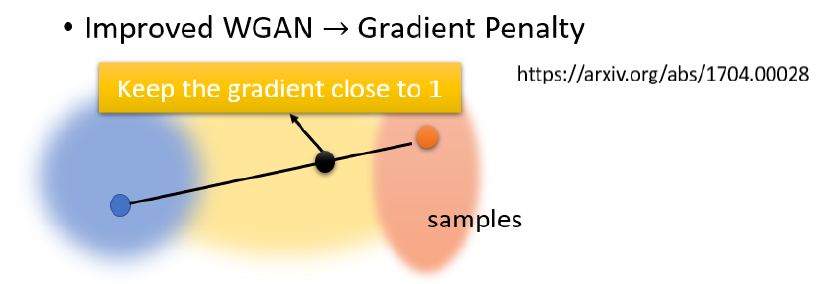
Gradient Penalty 是出自,Improved WGAN,大概的意思是:
分贝在real data 分布和fake data分布中各取一个sample,在两点连线中间随机取一个 Sample,并要求这个点的 Gradient 接近1,具体理论可以看paper解释。此外,也可以使用Spectral Normalization真的把 D 限制,让它是 1-Lipschitz Function。